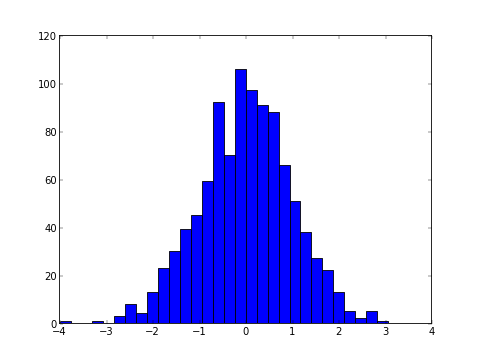
棒グラフ¶
棒グラフの描写¶
棒グラフの描写は plt.bar() で行います。 引数には2つのリストが必要です。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
X = [1,2,3]
Y = [3,1,4]
plt.bar(X, Y)
plt.show()
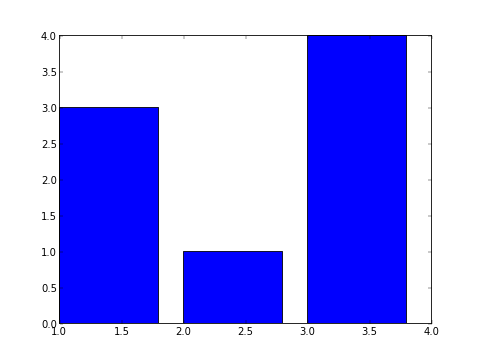
1個目の引数 X が棒の左端、2個目の Y が棒の高さを指定します。
実際の棒グラフのX軸は、数値ではなく名 (地名とか) の場合が多いですね。 そこでx軸の目盛りの書き換えを plt.xticks() で行います。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
X = [1,2,3]
Y = [3,1,4]
plt.bar(X,Y)
plt.xticks(X, ['Tokyo','Osaka','Nagoya']) # 目盛りを数字から地名に書き換える
plt.show()
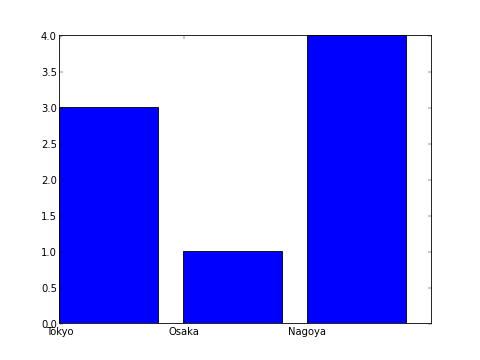
ただ、このままだと地名がグラフの左端に出てしまって美しくないので、 plt.bar() に align=”center” と記述するとセンタリングが行われます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
X = [1,2,3]
Y = [3,1,4]
plt.bar(X,Y, align="center") # 中央寄せ
plt.xticks(X, ['Tokyo','Osaka','Nagoya'])
plt.show()
複数データを横に並べて表示¶
matplotlib の棒グラフは (棒のくせに) x軸もy軸も手動で指定するという厄介なものです。 しかしその反面、複雑な形状の棒グラフも自在に描写できるという利点があります。
たとえば 「2012年と2013年のデータを並べてグラフにする」 といった場合は
- 棒の幅を 0.4 にする
- 2012年のデータを、X座標 1.0, 2.0, 3.0 に表示
- 2013年のデータを、X座標 1.4, 2.4, 3.4 に表示
- データ名を、X座標 1.2, 2.2, 3.2 に表示
といったことをします。 棒グラフの幅は plt.bar() の width 引数で指定できます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
X1 = [1,2,3]
Y1 = [3,1,4]
X2 = [1.4, 2.4, 3.4]
Y2 = [1,5,9]
# 2012年のデータを青で表示
plt.bar(X1, Y1, color='b', width=0.4, label='2012', align="center")
# 2013年のデータを緑で表示
plt.bar(X2, Y2, color='g', width=0.4, label='2013', align="center")
# 凡例を表示
plt.legend(loc="best")
# X軸の目盛りを書き換える
plt.xticks([1.2, 2.2, 3.2], ['Tokyo','Osaka','Nagoya'])
plt.show()
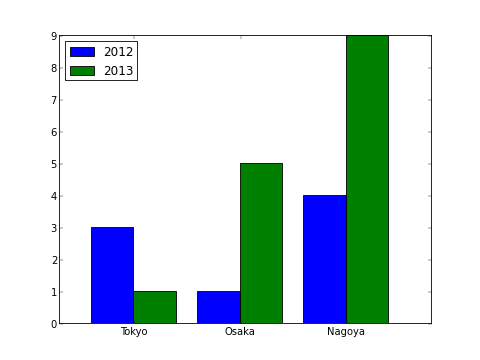
ただ、いちいち各X座標を0.4ずつずらすのは面倒なので、 ここは Numpy を使ったほうがスタイリッシュに書けます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
w = 0.4
Y1 = np.array([3,1,4])
Y2 = np.array([1,5,9])
X = np.arange(len(Y1)) # [0, 1, 2]
# 2012年のデータを青で表示
plt.bar(X, Y1, color='b', width=w, label='2012', align="center")
# 2013年のデータを緑で表示
plt.bar(X + w, Y2, color='g', width=w, label='2013', align="center")
# 凡例を表示
plt.legend(loc="best")
# X軸の目盛りを書き換える
plt.xticks(X + w/2, ['Tokyo','Osaka','Nagoya'])
plt.show()
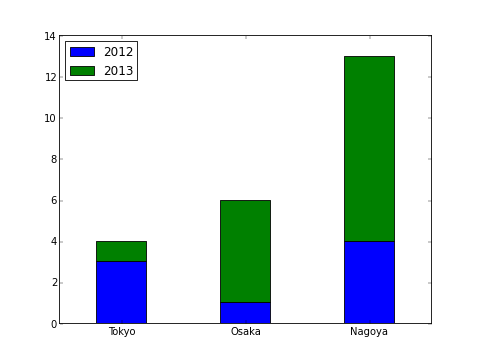
複数データを縦に並べて表示¶
plt.bar() の bottom 引数を指定すると、棒グラフの底の位置をずらすことができます。 これを用いると、複数データを縦に並べることができます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
w = 0.4
Y1 = np.array([3,1,4])
Y2 = np.array([1,5,9])
X = np.arange(len(Y1)) # [0, 1, 2]
# 2012年のデータを青で表示
plt.bar(X, Y1, color='b', width=w, label='2012', align="center")
# 2013年のデータを緑で表示
# 底の位置を Y1 だけずらす
plt.bar(X, Y2, color='g', width=w, bottom=Y1, label='2013', align="center")
# 凡例を表示
plt.legend(loc="best")
# X軸の目盛りを書き換える
plt.xticks(X, ['Tokyo','Osaka','Nagoya'])
plt.show()
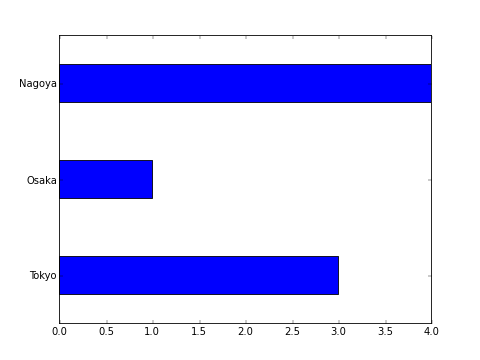
横向きの棒グラフ¶
plt.bar() の代わりに plt.barh() を使うと横向き (horizontal) のグラフになります。 縦向きで width と指定した棒の幅が、こちらでは height になるのでそれだけ注意しましょう。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
plt.barh([0,1,2], [3,1,4], height=0.4, align="center")
plt.yticks([0,1,2],["Tokyo","Osaka","Nagoya"])
plt.show()
ヒストグラムを表示¶
データの頻度分布を表示するヒストグラムに関しては、 matplotlib に最初から plt.hist() というメソッドが用意されているので、 これをそのまま使えば簡単です。
Numpy で乱数を発生させ、そのヒストグラムを作ってみます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
# 標準正規分布にしたがって乱数を1000個生成
data = np.random.randn(1000)
# ヒストグラムを表示 binの数は30個
plt.hist(data, bins=30)
plt.show()